
Breakdown of H100s for Transformer Inferencing
This new Nvidia GPU just dropped! This post will analyse what it offers for transformer inferencing.
specs
Here's a spec table to start. The "16-bit format" refers to BFLOAT16 and FLOAT16 while "8-bit format" refers to FP8 or INT8. For INT8 they aren't actually flops, because the "fl" is for float, but I'll continue referring to them as flops because we don't care about the difference for this context. Also the A100s only support INT8 and not FP8.
A100 40GB PCIeA100 80GB PCIeA100 40GB SXMA100 80GB SXMH100 SXMH100 PCIe 16-bit format Flops312TF312TF312TF312TF1000TF800TF 8-bit format Flops624TF624TF624TF624TF2000TF1600TF Capacity40GB80GB40GB80GB80GB80GB GPU Memory Bandwidth1.5TB/s1.9TB/s1.5TB/s2TB/s3TB/s2TB/s Communication Bandwidth300GB/s300GB/s300GB/s300GB/s450GB/s450GB/s Max Number GPUs With Fast Connections881616256256
The communication bandwidths are half of what's reported because I like to use the bidirectional number when thinking about model parallel communication cost. I discuss this in "Transformer Inference Arithmetic".
There's another relevant spec in here, where "up to 256 H100s can be connected to accelerate exascale workloads". For A100 PCIe this was up to 8 and 16 for for the SXMs.
how to get the 30x
Nvidia claims 30x higher than A100s for the 530B model ("Up to 30X Higher AI Inference Performance on Largest Models", "H100 to A100 comparison"). Let's see if we can decipher how they get that number, and where the speedups come from (none of the specs change that much!). Deriving estimation equations from this post, starting with large batch sizes. A large batch size means a number higher than the hardware ratio of flops to memory bandwidth. On the 40GB A100s that's 208 and for the H100 SXM (by default, when I say H100 I'll mean the SXM) it's 333. We care about the large batch size because we will be flop bound instead of memory bound. The comms is thoughput + latency, but we'll drop the latency which is small. These equations measure running one token through all the blocks in the model.
We calculate two numbers because we have a sense of compute vs communication bound. Sometimes we might add these numbers together, so for this post we'll consider both. There's a factor of 2 in comms that will get dropped for 8-bit formats.
The Megatron arch is 105 layers, 20480 embedding dimension. We'll start with batch size 512 to get us flop bound.
Technically nothing stops us from 8-bit on A100s, but F8 is going to be a lot easier to use than INT8 quantisation so I think it's reasonable to include the speedup from that availability. We can't use 32 A100s because we don't have the hardware to communicate between that many A100s quickly.
To attribute all the speedup: 1.7x from going from 16 to 32 chips if we do overlapped comms and compute. 3x from flops difference. 2x from going to 8-bit. Note that the 2x from going to 8-bit might not be exhausted, as we may not want to 8-bit everything to keep model quality up. Also because maybe the practical bandwidth (compared to the theoretical ones, which is whats in the spec) of the 8-bit is lower than the 16?
And here we get a 11x speedup for overlapped comms|compute and 9x for synchronous comms|compute, so we're missing something! Nvidia doesn't give that much spec as to how the benchmark was run, other than
Projected performance subject to change. Inference on Megatron 530B parameter model based chatbot for input sequence length=128, output sequence length =20 | A100 cluster: HDR IB network | H100 cluster: NVLink Switch System, NDR IB
I think they're also comparing against different batch sizes like they do here because the maximum batch size also changes.
We need at least 16 A100 GPUs for a 530B model, as the weights in BF16 will take about a terabyte (we need the 16x80=1280). It does mean that we only have 1280-530x2=220GB remaining. For F8 on 32 GPUs, we have 80x32-530=2TB remaining. When we sample from large language models, we store kv per token, and the benchmark has them doing 148 tokens.
For 16-bit, thats 2x2x105x20480x148 = 1.27 GB per request. For 8-bit it's half, for 0.64GB per request. What this says is that our 220GB remaining only fits 170 requests, while the 2TB can fit somewhere in the thousands. Then, they're probably comparing for the time to complete the same number of requests, but the A100 would have to do it in two batches. Because the 170 is under 208, it also means that our A100 inference is memory bandwidth bound as opposed to flops bound. But it's also probably much less than 170! A bunch of weights might be duplicated across GPUs, and software loses some memory (having TF load a 40GB A100, TF thinks there's only 38.4GB available). So maybe only 190GB remains and we fit ~150 requests.
For convienence, lets say we're doing time to complete 450 requests. I'll leave out comms on the 16 A100s and assume compute bound. There's no factor of batch in the compute anymore because at memory bound, we only count time for loading weights.
Now we get 44x3/9 = 14.7x. We're still missing 2x, though we got closer than last time (10x). We can bully here a bit -- what if we measure the time for 451 requests? Then we'd still get 9ms for the 32H100s but then the 16A100s would take 44x4=176ms, giving us a 19.5x difference. It's actually also probably higher than 44ms, since the memory boundedness isn't absolutely independent of batch size, the intermediate calculations are expected to do a number of round trips through memory. The scale of this in practice is less than 10% slower due to those operations.
Another possible cause of the time difference is that 16 A100s is actually comms bound, and might be way higher than 44ms. The spec says it's HDR Infiniband. When I put 16 in the table, it's actually only for HGX and not DGX, where these are systems that determine how many GPUs we can link quickly. DGX can only do 8, so maybe Nvidia did that!
Infiniband is at most 600 gigabits per second, or 75 gigabytes per second. That's a 12x difference! That would mean that the comms time (which we expect to be 9ms throughput, 2ms latency) would take 11*12=132ms, making the A100 setup very comms bound (but we can't do less comms due to capacity). 132x3/9 = 44, which is uhh too high. If we use the mean batch numbers, it's actually 59x.
Transformer Engine utilizes FP8 and FP16 together to reduce memory usage and increase performance while still maintaining accuracy for large language models.
Some of that might be smaller, because maybe not everything is F8? This is also unspecified. If say 50% of their weights were half precision (or specifically, 50% of their computations were half precision) then that would get us exactly 30x. I mean, it seems Nvidia hasn't benchmarked yet, this is all "Projected performance subject to change".
It's also possible that Nvidia doesn't do tensor parallel because of that massive comms time, rather it would do pipeline parallel, where the layers are split across GPUs (first GPU will have first N layers, last GPU will have last M layers). This way, we can have two hosts with 8 GPUs each, and the expensive comms only has to happen once per model pass, instead of four times per layer.
In this case we might want to do something where we pretend the first 50 layers are "one model", do that tensor parallel on one host and then do the last 50 layers as "one model" with an extra communication time in the middle. We can predict that this will not be comms bound, it'll be the same 11 ms between the fast-connection gpus, and then almost nothing for that jump in the middle (which would be 132/(105x4)).
But the compute time here does go up! Just not by twelve times. For a half-model unit, we'll have half the bytes but also half the memory bandwidth, so each model would take 44ms. That does somewhat take our times to double, but not quite. For a batch size of 150, it would in fact take double. But to do three of those batches, we'd only take 4x44ms.
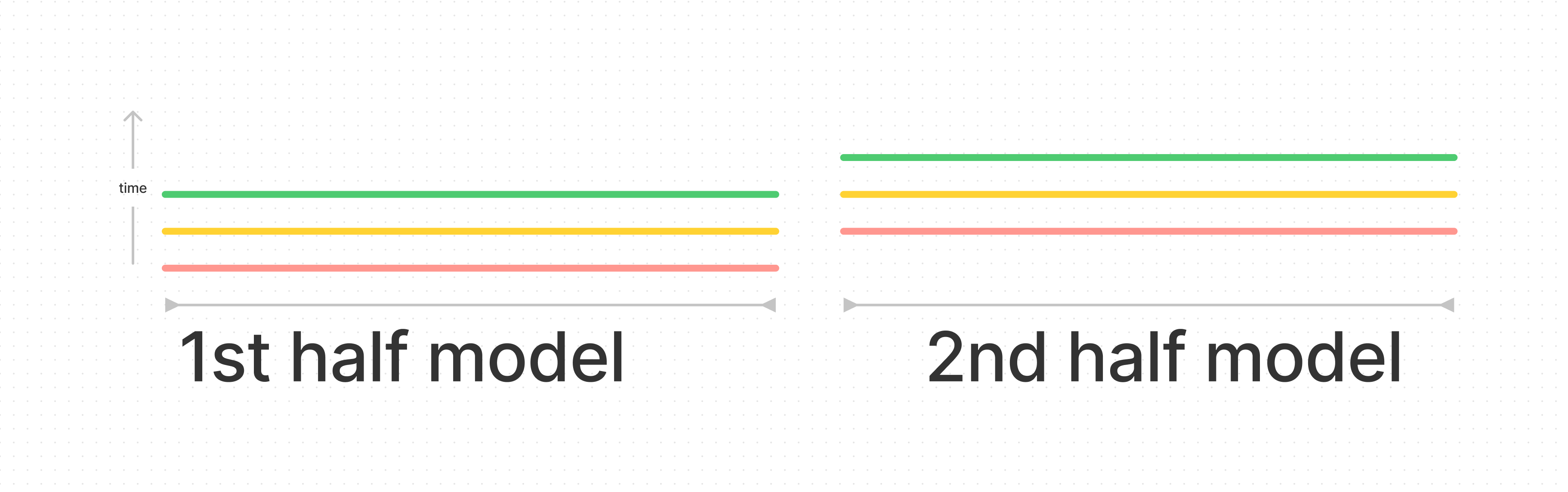
For that, when the first batch is processing on the second gpu, then the second batch can start processing on the first gpu, hence the "tensor parallel". All in all, three batches would take 176ms. 176/9=19.5 again (it's the same effect we get when we bully with the number of requests we're measuring). I'm not going to calculate it, since it'll be a similar order of magnitude, but there's also a different speedup associated with doing the compute and comms synchronously (in this case, we could insert 128 H100 GPUs).
The intermediate calculations + kv cache reads that we don't factor in are somewhat significant. We don't know what the paralellism setup is, or if they factored in the in-practice bandwidth of F8 vs F16, or how much this Transformer Engine uses F8 vs F16 but I think I've at least exhausted all the major mechanisms through which the 30x speedup can be acquired.
Summary
Here is a list of all the speedups that can occur with H100s for large language model inferencing (sometimes applicable to training as well).
A100s can only connect up to 16 GPUs with fast communication, while H100s can do up to 256. This means that any model that was not already comms bound at 16 chips can have more chips.
The flops are higher by 3x, so for flops bound operations that's 3x
The memory bandwidth is higher by 2x, so for memory bound operations it's 2x
Being able to have more chips may be the difference between being memory bound (less chips) and being flops bound (more chips) as there's more capacity left over to store kv cache for sampling.
Having F8 enables people to easily use 8-bit precisions, halving the compute whether it's memory bound or flops bound.
Some models may be forced to use more than the max 16 chips due to capacity, meaning they'd be heavily comms bound as host to host comms are extra slow. That slowness would be lifted with the 256 for H100s.
spin me in weight space
paint me in half precision
we're best in chaos